Your recent Google Search roll-out is suffering serious backlash: at this point, I think we can all agree with this. I decided to write this open letter because I am a critical, but friendly voice: I am an interested party with a professional stake in Google remaining stable and the bedrock of web search. I am one of your proverbial power users, who ditched Microsoft and adopted Linux specifically to better host the Gemini ecosystem where I built my project and all my workflow. The roll-out never affected me, and that is one of the points of this argument: the problem is not your system. It works great for us, and it wasn’t even new: we’ve been using these features for months. But your audience architecture isn’t working.
Most of the people out there writing and talking about it are using some variation of the “mainstream” ChatGPT-Claude combination, and are speaking from a different perspective (which, by all means, you should take into account). I am a different animal. My digital life takes place inside your Gemini ecosystem. My experience with your system is different and deeper.
This isn’t a marginal problem: while the public is currently reeling from the global rollout of Gemini 3-powered “AI Mode,” the architecture of this shift actually began in March 2024. I was an unwitting subject of that early unlabbed test group, using these features smoothly for months. The current panic is not about a new technology. It’s about the visual demotion of the “Ten Blue Links” from a primary feature to an invisible footnote, specifically on mobile viewports where an AI block combined with sponsored ads taxes the user two to three full screens of scrolling before the first organic link appears.
Let’s review what happened, and how it was received by the general user. Then, let me tell you where I am coming from to better elaborate on the argument that you have built a brilliant tool for people who think like database managers but forced it live by default onto a public that lacks the necessary cognitive toolkit. They are right to resent you and they are showing it by shifting to DuckDuckGo.
I think you can fix this, and I will offer my suggestion.
What happened
One of the things that this episode revealed, I think, is that Google Gemini users relate to AI assistants differently from users who primarily work with the mainstream ChatGPT+Claude combo, for example. For them, an AI assistant chat box is an AI assistant chat box, no variation, no nuance. They have their agents, their APIs, and they know what to expect in that particular output window.
For us, it’s not. The whole ecosystem is Gemini–powered, but if I am asking my assistant to compare theoretical models that I uploaded as pdf documents to NotebookLM, or if I’m just typing a simple search expression – say “Cytochrome p450” – to the Google Search box, I get entirely different interaction experiences. Google testers and power users were exposed to AI overview, then to the first versions of AI mode gradually, and we had time to figure out how they worked and how to incorporate them. It happened throughout several months and it was smooth.
FIG 1 – Initial search query on Cytochrome p450 showing the layered layout
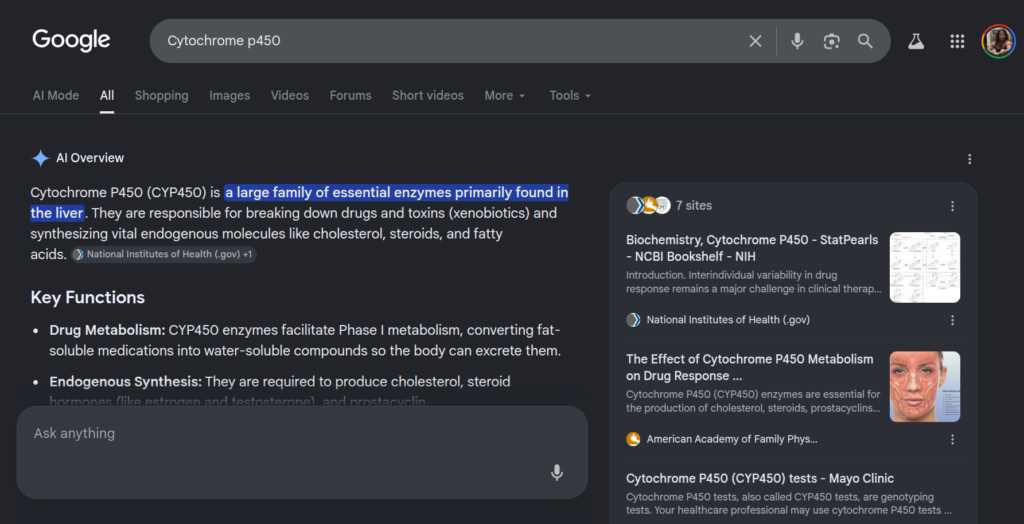
Figure 1: Desktop interface layout of a Google Search for “Cytochrome p450” demonstrating the multi-layered geometry of the modern search interface, where an automated synthetic text block occupies the primary viewport above traditional indexing lines.
This matters a lot because the general public views Gemini in Search as the same chatbot they access in a dedicated platform in any of the competing models out there. You have not told them about Retrieval-Augmented Generation (RAG), and that when they type a search, it doesn’t go straight to the LLM. A smaller model translates the human query into an optimized database search string. Google runs its classic search algorithm to pull the top 10–20 web pages. These web pages are chopped up into text snippets and fed into Gemini’s “context window” as a prompt. Gemini is essentially told: “Read these 20 snippets and write a 4-sentence summary. Do not use your own internal knowledge.” Another independent model checks Gemini’s output for safety, hate speech, or extreme policy violations before showing it to the user.
FIG 2 – Vertical scrolling view of the Cytochrome p450 search results, part 1
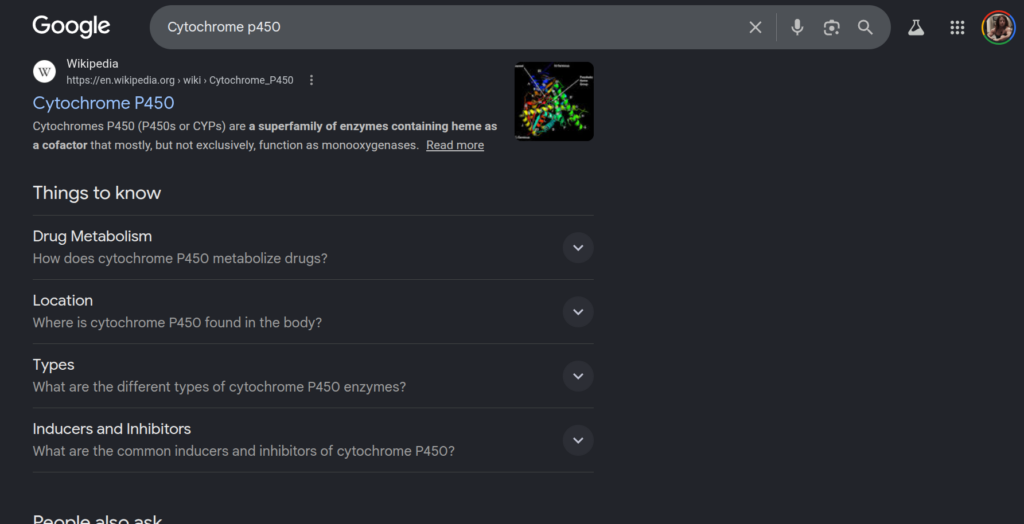
Figure 2: Analysis of the desktop search viewport showing the vertical expansion of intermediate informational blocks, which forces independent publisher URLs down the page sequence.
FIG 3 – Vertical scrolling view of the Cytochrome p450 search results, part 2
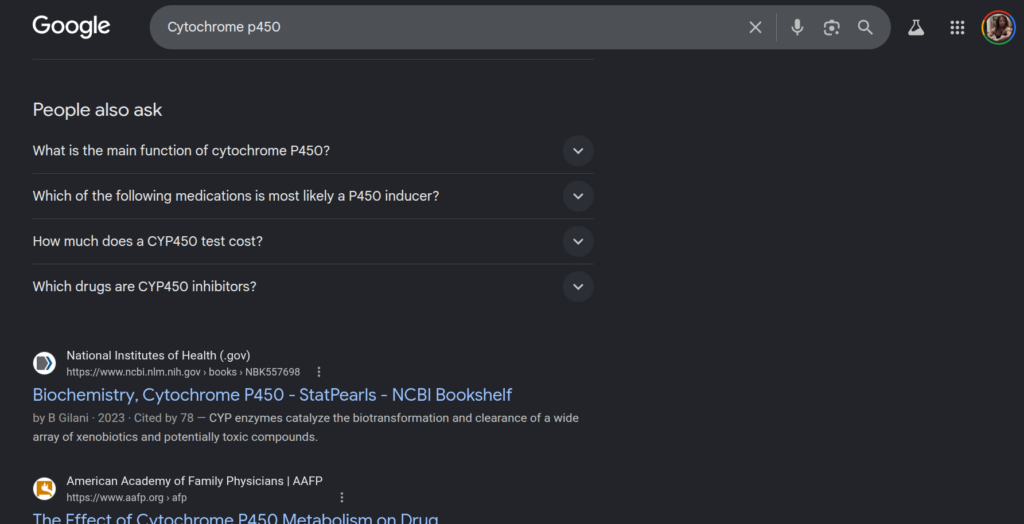
Figure 3: Further vertical scrolling mapping of the search interface, showing the ultimate placement of traditional indexing entries beneath structured query features and interactive modules.
You tuned the RAG system to high value engagement and recency. It failed to properly separate satire from authority. When a user asked how to keep cheese on pizza, the system grabbed a 10-year-old sarcastic comment from a Reddit troll (“add glue”) and synthesized it as a definitive truth because it lacked the semantic depth to understand human sarcasm (it’s not the advanced model).
I didn’t know all these details, but it never bothered me (and, I’m assuming, other Google regular users) because it was intuitive: after a couple of times using AI overview, it’s easy to figure out how to prompt it, and that it is fundamentally different from AI mode or the other dedicated chat assistants.
The disaster is that most casual Google users were not exposed to the several layers of AI presence in the search function until last month, May 2026. When they were, the experience was brutal and utterly confusing: suddenly it was no longer just a summary at the top; for many queries, the entire page was then AI-generated (“AI Mode”), pushing traditional links even further down or nesting them into conversational flows. Users felt links had been “eliminated” – visually, they feel demoted to footnotes. To make it worse, millions of standard everyday users had this experience on their phone, where the physical real estate of the mobile viewport meant that links were pushed far down the output, requiring multiple deep manual scrolls just to discover a publisher URL. For no fault of theirs, they are helpless to handle this format because they lack the cognitive tools to “see through” and manage what you deliver to them as output.
The Freak Out
Users freaked out with what I think can be classified as a clumsy and rushed roll out. They felt stripped of their basic agency as they interacted with information, they felt gaslit, and they felt betrayed: you radically changed an experience that they counted on as the foundation of web search for decades.
Traditional Search (Deterministic Framework):
[User Input] ──> [Query Engine] ──> [Index of Independent Links] ──> [User Evaluates & Selects]
Result: The user is the active investigator. High agency.
AI Overview (Interstitially Imposed Framework):
[User Input] ──> [Google Synthesizer] ──> [Single Omniscient Answer]
Result: The user is a passive recipient. Low agency.
It seems that the dread comes from three psychological friction points:
- The Loss of the “Deconstructable Answer” (Opaqueness): Google Search was not unlike a library, where the user retrieves a catalog of books from which they can choose which to trust. Google replaced the catalog with a synthesis that commands trust without disclosing its process, failing miserably and triggering immediate subconscious claustrophobia.
- The Gaslighting Effect: When the oracle hallucinated, users felt even more distrust, and a sudden loss of digital ground. If the utility company that maps their digital world suddenly insisted that eating rocks was healthy, the tool started feeling like an unstable entity.
- The information ambivalence: When users go to Google, they want raw indexing. By forcing synthesis everywhere, Google triggered a psychological rejection to the mixing of two entirely different cognitive modes (Browsing vs. Converse).
Timeline
For the benefit of the reader, here is the timeline for the Google search AI changes:
- May 2023 (The Lab Phase): Google announces “Search Generative Experience” (SGE). It is opt-in only.
- March 2024 (The “Unlabbed” Test): Google begins testing AI Overviews on a small percentage of US users who did not opt-in. (This is likely when I first encountered it).
- May 2024 (The “Glue on Pizza” Era): The first official mass rollout of AI Overviews in the US.
- The Features: Text summaries at the top of results, answering complex questions.
- The Crisis: The system hallucinated (e.g., “eat rocks”), causing the first wave of public distrust.
- October 2024 (Global Expansion): The feature goes live in 100+ countries.
- May 2026 (The Current “Big Cry” – AI Mode): Google rolled out Gemini 3-powered “AI Mode” updates globally.
The user base is experiencing a mixture of UI fatigue, loss of agency, and AI skepticism.
- Loss of Control: Traditional search is active; the user queries, scans, evaluates, and chooses where to click. AI search is passive; it hands the user a pre-chewed answer. Power users/regular users know how to bypass or handle this; casual users feel trapped by it.
- The “Glue on Pizza” Viral Crisis: When the feature rolled out globally, the AI famously hallucinated dangerous advice, telling users to use non-toxic glue to keep cheese on pizza or to eat rocks. While these were edge cases, they completely shattered public trust in the reliability of the AI Overview.
- The “Enshittification” Perception: Rightly or wrongly, the public perceives that search quality is being degraded to save Google data center costs, push more ads, and keep users trapped on Google-owned pages rather than letting them freely explore the web.
The backlash was predictable and immediate: DuckDuckGo reported a 30% surge in U.S. app installs in the weeks following Google’s announcement. On iOS devices, DuckDuckGo saw a 33% average increase in installs, with single-day spikes reaching as high as nearly 70%. Traffic to DuckDuckGo’s dedicated, AI-free search page more than tripled. This represents an immense pool of millions of pissed off users actively fleeing an environment that stripped them of their autonomy.
The product is good, but the roll out was clumsy
There is nothing wrong with your AI overview and even less with the AI mode. Together, the traditional search, the AI overview and the AI mode, particularly when the user becomes skilled at prompting each instance, adding personalization and context, and selecting sources, is pretty awesome.
In fact, of all Gemini’s “sub-personalities”, the one that “won” me and convinced me of the incredible power of the technology, at first, was the native Search Agent capability (the AI Mode with access to my workspace). From there I went to the AI Studio and, in September 2025, I got a paid subscription. Today, my whole professional activity and my health are coordinated from the central dedicated window with the Gemini3.0 powered assistant, with several NotebookLMs (and their assistants), several projects (and their assistants) and Gems.
I think each one of us develops their own method to navigate the Gemini ecosystem and mine is this. Regardless of how we make it ours, we are constantly aware of each assistant and each agent. There is a lot to evolve here, but it works for people like me.
It doesn’t just work for me because I was a lucky chosen tester, but also because of my previous experience, which matters because what I had, and most people lack, can be easily taught. Or at least sufficiently taught.
A 40-Year Relationship with the Database
Searching things in databases is something I’ve done at a sophisticated level most of my life. I’m a scholar who went to school in the early 1980’s, who defended a Master’s thesis in 1989 and a Ph.D. in 1994. An exhaustive literature review used to take months with several hours a day in the library, handling cardboard cards and infinite piles of draft paper to organize the information. Both my degree monographies involved bibliometric analysis itself (metaanalysis), which forced me to develop my strategies and also to learn methods of bibliometric analysis, and later scientometric analysis.
When I got to the doctorate stage, I had access to the databases in the mainframe of our university’s computer system. It was a revolution for me, and I learned how to do boolean searches. From the terminal searches I’d go to microfilms and then back to the terminals. Forty years ago, users had to understand intersection, union, and exclusion to pull data from mainframes. Eventually I taught this. Eventually I conducted scientometric research.
The casual untrained user types natural language, entirely unaware that a backend rewriter is still trying to convert their words into optimized database strings.
For people like me, data searching is second nature. When I’m done with work, I search stuff for fun. I can “see” what is behind my searches because I’ve seen and been part of the technological route that got us here, even when I can talk to my assistants as if the microphysics of how they process my utterance and the microphysics of how I generate it don’t matter. I can treat them as opaque. They are not, though. And I am offering the transparency of this process as a way to identify actions that will approximate the casual user’s experience to mine. I tell this story to prove a point: I possess a structural mental model gradually developed in 40 years of familiarity with databases and data retrieval. The casual users are failing because Google hid the scaffolding that allows a human to climb the data pyramid.
We can bridge that gap.
The Specialist Workflow (Case Study: PubMed vs. Google Scholar)
How this approach works becomes clear when analyzing a technical search workflow. Around a year or two ago I noticed that the specialized medical database PubMed’s search engine degraded significantly, failing to surface relevant items efficiently. My work requires me to search medical and social databases on a daily basis. PubMed’s search engine deterioration was a problem. I adapted by bypassing PubMed’s native search, using Google Search to catch the high-level intent, leveraging the AI Overview to verify the semantic landscape, and anchoring the final data pull in Google Scholar. Google AI overview usually does a great job at that, and if the search lacks precision, I automatically jump into AI mode and solve the problem.
Here is a demonstration of this operational breakdown using a basic conceptual query – “reticular activating system”, showing the architectural divergence between an ungrounded search interface and a robust AI-assisted pipeline.
FIG 4 – Google Search box with AI Overview for reticular activating system
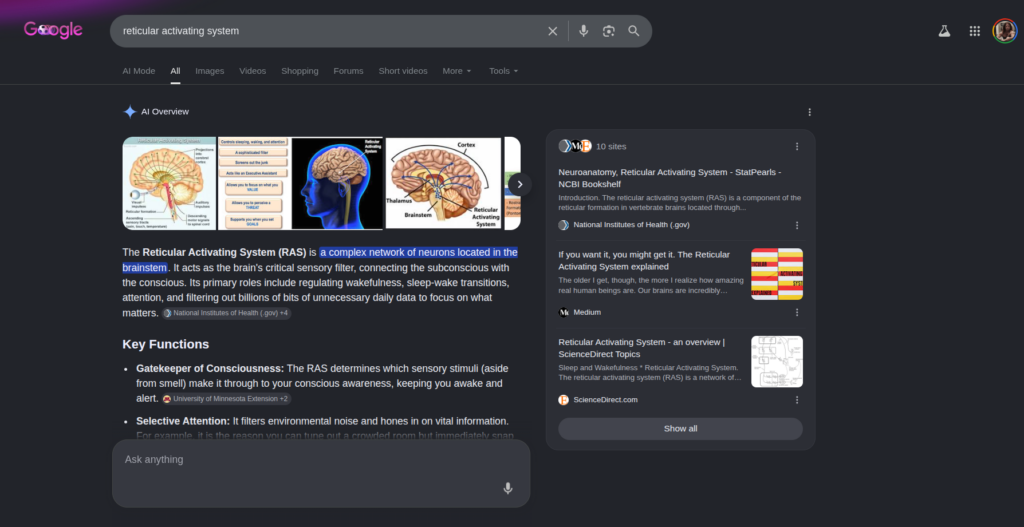
Figure 4: Desktop view of a standard Google Search for “reticular activating system.” The AI Overview delivers a highly accurate semantic summary paired with immediate citations from authoritative repositories like the National Institutes of Health (NIH).
When entering the exact same conceptual phrase into the specialized PubMed interface, the system breaks down. It defaults to treating the query with loose operators, returning a massive volume of irrelevant literature that misses the intended context.
FIG 5 – Simple query on PubMed displaying irrelevant results
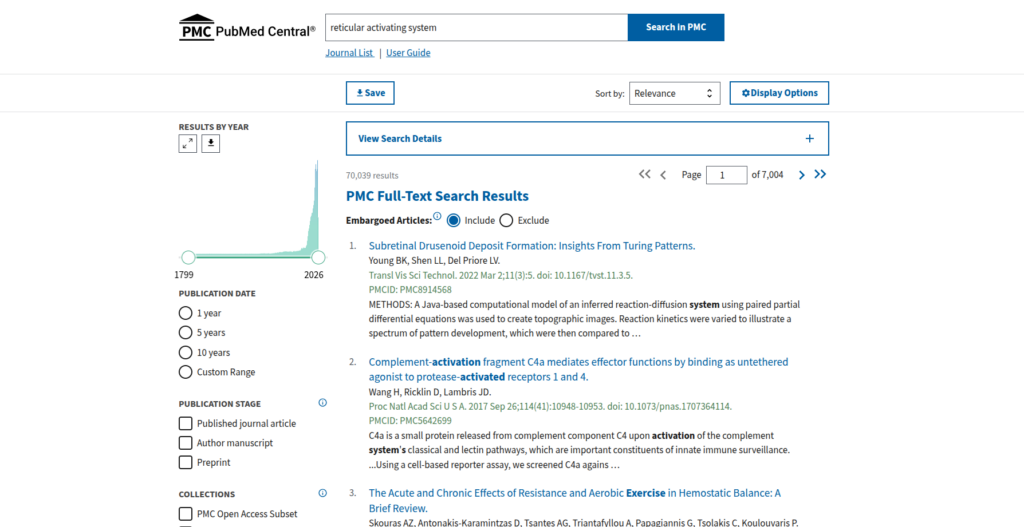
Figure 5: Native PubMed Central full-text search results for the unquoted query “reticular activating system.” The engine returns over 70,000 highly unguided results, misaligning relevance by failing to prioritize primary system conceptualizations.
Even when employing a consolidated search string with explicit grouping parentheticals to discipline the query engine, PubMed continues to surface returns that lack contextual precision.
FIG 6 – PubMed search with a consolidated search expression
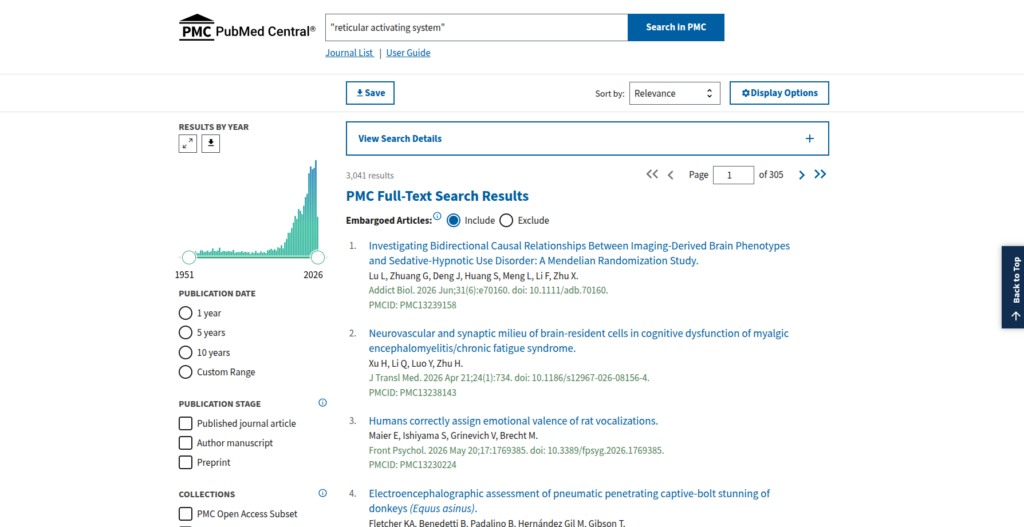
Figure 6: PubMed Central results utilizing a disciplined search expression. Though trimmed to 3,041 results, the top indexed papers remain weakly aligned with the core structural literature.
By contrast, bypassing the native medical database engine and entering the simple conceptual query directly into Google Scholar restores structural precision. The underlying algorithm immediately surfaces foundational text, historical breakthroughs, and primary literature.
FIG 7 – Simple query on Google Scholar
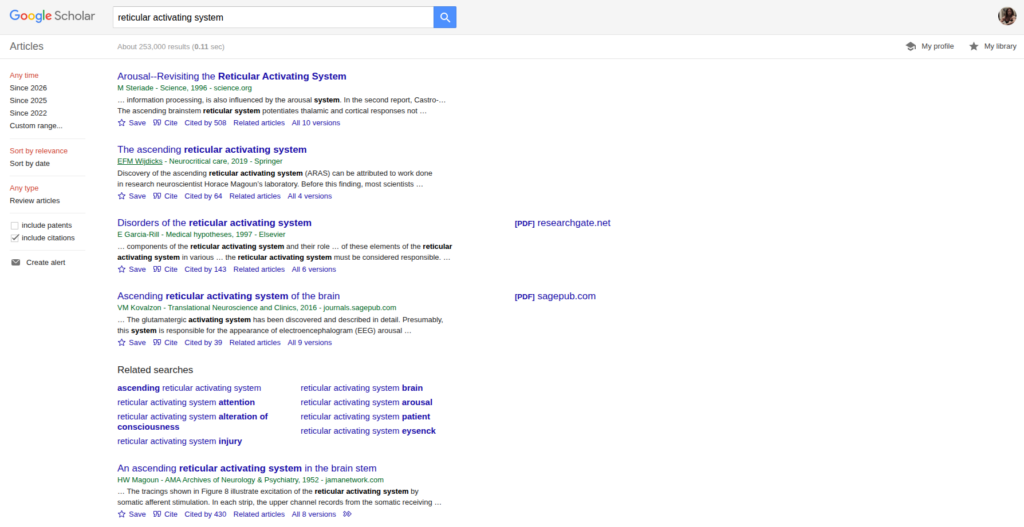
Google Scholar interface for the unquoted query “reticular activating system,” demonstrating immediate precision by surfacing core historical and structural texts (e.g., Steriade, Wijidicks, Garcia-Rill).
This accuracy remains intact even when checking the most recent literature. Restricting the timeline to 2026 shows that Google Scholar cleanly isolates contemporary, relevant developments in neuro-modulation and physiological pathology.
FIG 8 – Simple search on Google Scholar filtered for 2026 literature
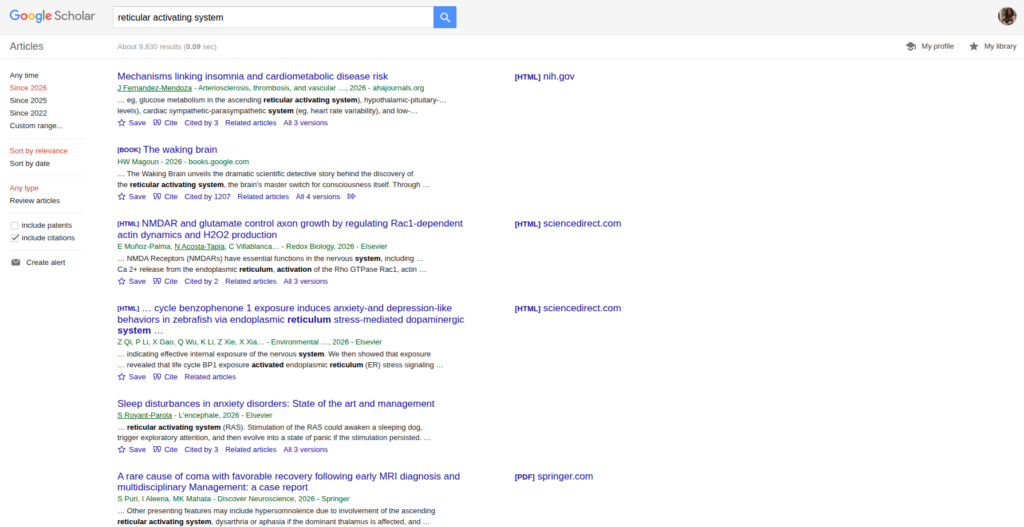
Figure 8: Google Scholar query filtered exclusively for the current 2026 publishing year, displaying coherent technical continuity within contemporary sleep and autonomic literature.
Finally, when deploying a fully consolidated, quoted search expression within Scholar for 2026 literature, the engine perfectly isolates highly specific contemporary studies detailing structural dynamics and clinical consciousness networks.
FIG 9 – Consolidated search expression on Google Scholar for the year 2026
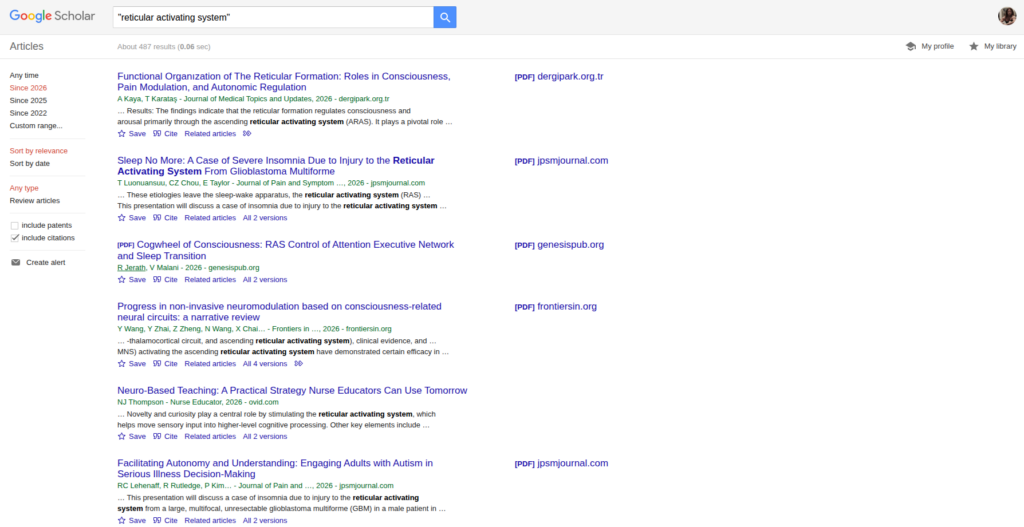
Figure 9: Google Scholar interface utilizing strict quoted constraints for 2026 publications, successfully isolating highly specific clinical frameworks.
PubMed search has become functionally irrelevant even to an investigator who can construct detailed queries with boolean operators. On Google Scholar, paired with Google’s intent-capture structures, I obtain the exact documents I was looking for. Even highly specialized tools can degrade, forcing power users to build alternative, hybrid pipelines. The Gemini ecosystem is great for that.
Maybe because of this background and my luck of being an early adopter and having time to develop my strategies, I eventually figured out strategies to help the model avoid hallucinations. You may find my language strange: “help the model avoid hallucinating”. It is deliberate: I find that whenever any of them hallucinates, and that hasn’t happened at all in 2026 yet, I can identify the cause in my prompting or in my bad context management. I had time to figure that out and also to formally learn, but we can teach enough of this to make the casual user’s life easier.
I feel these things evolved organically. At one point, I realized that to do what I needed with my assistants was hard without cluttering the context with loose ends that forced the model to integrate unrelated items and desperately fill a request without a clear path. There were strategies around that, but when Google released NotebookLM, it solved several of the problems. Later, Google released Projects, which, with their dedicated assistants (instances of the Gemini chatbot, or his “subpersonalities”), solved even more problems.
The more investments a user makes – acquiring a paid subscription, enrolling in courses to improve their skills, working with difficult problems that require workflow strategies -, the more committed they are. It’s easy for a committed user to wait for the roll outs and “evolve with the tech”. The casual user has a much lower tolerance.
FIG 10 – Interactive conversation window inside Gemini AI Mode
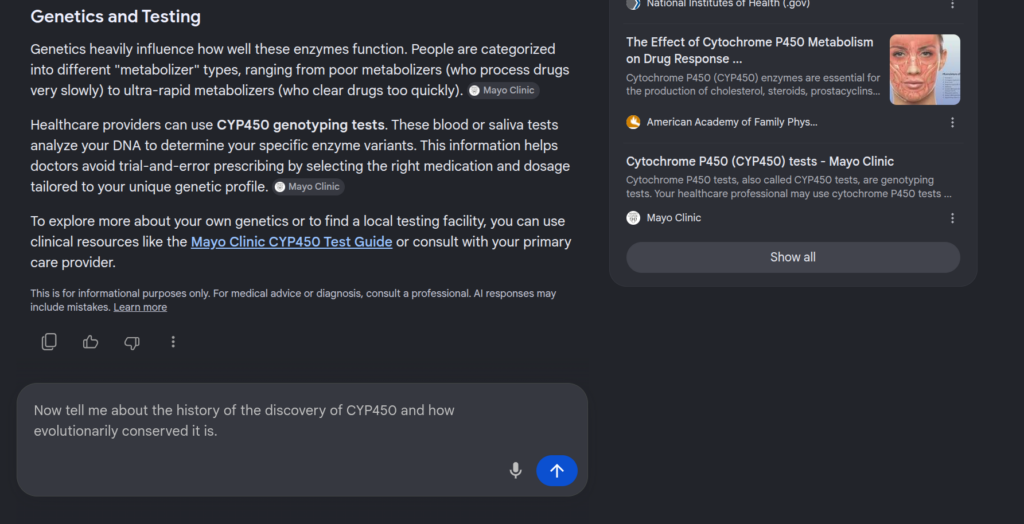
Figure 10: Interaction history within Gemini’s dedicated “AI Mode” conversational workspace, tracking a multi-turn deep dive into the evolutionary history and discovery timelines of Cytochrome p450.
FIG 11 – Detailed view of the evolutionary lineage output inside AI Mode
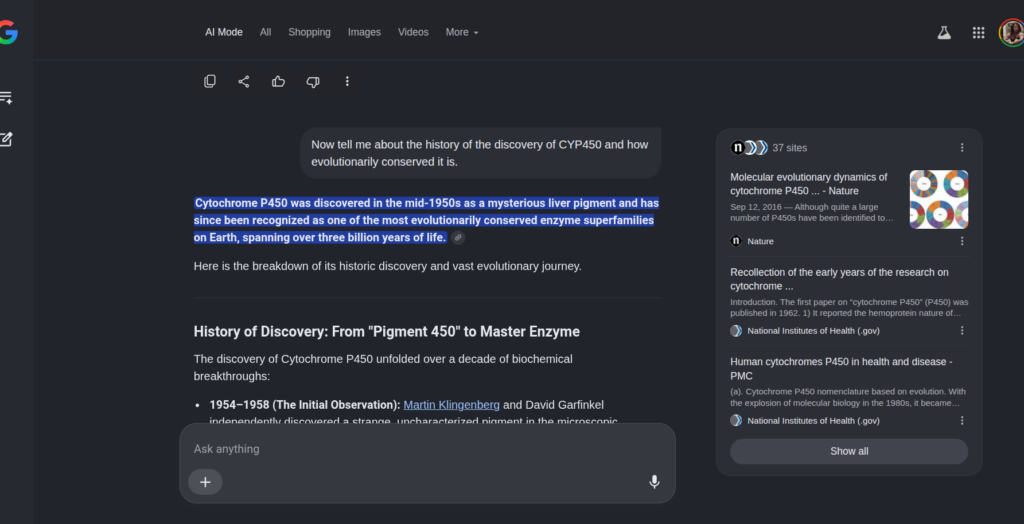
Figure 11: Continued deep-dive workspace view displaying the synthesis of highly specific historical benchmarks (e.g., Martin Klingenberg’s 1954 discoveries) generated within the conversational sandbox.
Users like me – power users, neurodivergent users, researchers, users who had more time with the models – now avoid potential search problems because of this experience. We intuitively frame queries to extract clean data; casual users input vague terms that easily trigger the RAG (Retrieval-Augmented Generation) system’s failure modes. We scan for domain authority; casual users lose agency when Google removes the visual branding of independent URLs.
The question for you is how to translate that into features that can eliminate the barriers for your casual users to have a full and positive search experience, and a smoother navigation of the Gemini ecosystem. The answer lies in shifting your philosophy from forced automation to user sovereignty. Your casual users are sitting at the passenger seat: you need to give them back the pilot dashboard.
The Cognitive Pre-requisites for AI Literacy in Data Search
AI doesn’t suppress creativity or critical thinking as long as you are equipped with certain things. In cognitive science and human-computer interaction, those “things” can be categorized into four specific pillars.
| Item | Power/Regular User | Casual User |
|---|---|---|
| Structural Mental Model | Knows the AI Overview is just a superficial layer processing a fixed dataset. | Treats the AI Overview as an omniscient entity or a fully enabled LLM. |
| Epistemic Vigilance | Cross-references text with existing knowledge bases. | Treats a single summary box as textbook fact. |
| Prompt Deconstruction | Intuitively frames queries to extract clean data. | Inputs vague terms that easily trigger RAG system failure modes. |
| Information Verification Literacy | Scans for domain authority. | Loses agency when Google removes the visual branding of independent URLs. |
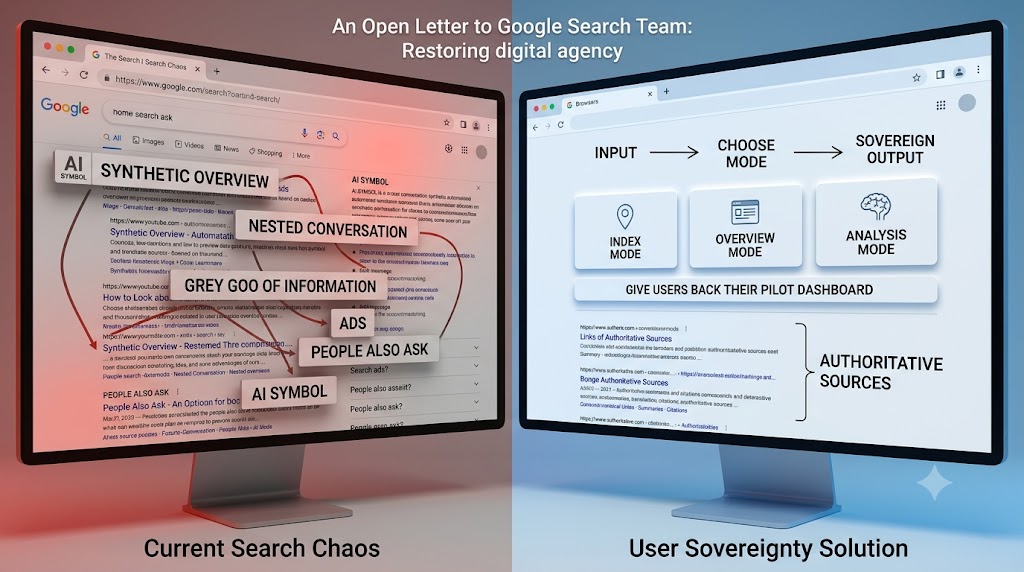
The Solution: Restoring Agency Through a Three-State Architecture, and Education
My question, as I was writing this letter, was how to use my experience to help those users. How can we approximate their experience to mine? What’s different? At this point, I’d say that I have the privilege of “seeing” what to them is opaque, and that I know things about searching that they don’t.
The Three Button Architecture
Google does not need to roll back its AI models. It needs to give users explicit sovereignty over their interface via three distinct, prominent mode buttons.
- Index Mode (The Map): The classic, deterministic “Ten Blue Links” with zero text generation. For casual scanning or fast domain verification.
- Overview Mode (The Connective Tissue): Synthesized paragraphs, but with reversed geometry: authoritative sources must sit parallel to or above the text, not hidden underneath dropdown arrows. This restores brand authority to publishers, allowing the human eye to calculate domain trustworthiness before reading the synthesized text.
- Analysis Mode (The Sandbox): A dedicated, deep, multi-turn reasoning workspace (like Gemini Advanced) that separates raw data ingestion from heavy logical processing.
Even with the choice, the same approach would have the engine default to Index Mode or Overview Mode based on user-defined account settings, or the system auto-detect “informational vs. navigational” intent, but allowing a one-click override.
FIG 12 – Interface simulation of the proposed Three-State Architecture
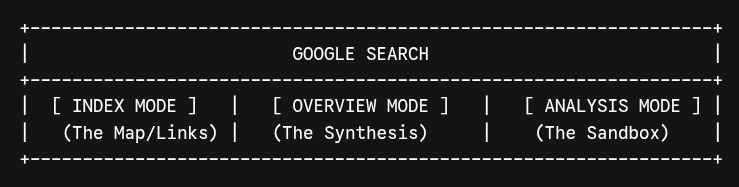
Figure 12: Visual simulation mock-up of the proposed Three-State Architecture interface, rendering the distinct mode selectors (“Index Mode”, “Overview Mode”, and “Analysis Mode”) directly beneath the central navigation utility to restore human agency.
The Micro-Education Blueprint
If Google wants a population of prompt-literate users who don’t freak out, you must actively teach them.
- The Learning Link: Add a prominent “Want to learn how to use this engine better?” link next to the AI features.
- The Content: This link should expose the basic multi-layered sorting structure of the engine, offer explicit rules for intuitive prompting, and invite them into deeper technical literacy.
Conclusion
Remember: while the standalone Gemini app has surged past 900 million monthly active users, and Gemini-powered search summaries hit 2 billion people monthly, the vanguard lies in the dedicated user base. Google’s consumer paid subscription ecosystem has reached 350 million users, driving a massive, high-leverage pool of human resources who actively invest in your platform. These users represent an immense cohort of pilots who want a hybrid, agentic (for both humans and AIs), integrated, multimodal, but also sovereign future. Forcing it on an unprepared public, though, damages trust in AI as a whole.
Google does not need to retreat from the AI frontier, nor should it, and making sensible changes aligned with the users’ sentiment and cognitive preparedness is sound product development. It’s a good product, but it needs fixes. They always do. For those of us who grew up pulling raw data out of command-line mainframes, the multi-layered capabilities of the Gemini search ecosystem represent a real, qualitative leap forward in information retrieval and synthesis, nothing short of a revolution. To remain in the “vehicle driving into the future” metaphor, you have unfortunately freaked out the pilot with your new cockpit. By replacing the traditional index with an unavoidable singular oracle, you stripped casual users of their digital agency. Give them back their user sovereignty. Give them the three-state architecture, with a clear choice between a Map, a Summary, and a Sandbox. If you want a world of AI-literate searchers who trust your platform (as they did before) to navigate the digital age (as you should), you must stop hiding the scaffolding. Teach them how to fly the machine, instead of forcing them to be passengers.